
This is a blog post which I wrote in relation to my presentation for the Ethical Innovation for Artificial Intelligence Workshop which took place from July 27th to July 28th 2020.
Click Here to view the video recording of my presentation
Ethical Innovation in Process Mining
I became interested in learning about Process Mining after a conversation with my now supervisor, Professor Arik Senderovich, which took place after a lecture of the Systems Analysis course he was teaching back in the Fall 2019 semester. We were learning about process modelling notations and how to draw an accurate model of processes using different gateways and lanes and he was telling me and another one of my classmates how there are computer programs which can automate exactly what we were learning to draw out and that his research is on how to capture more complex processes in this manner.
As an Anthropologist whose whole world revolved around handwritten notes, I was very curious to know how this all worked. I had the chance to explore this interest after Professor Senderovich agreed to let me take a reading course with him over the summer semester. During this time I was also working as a research assistant with him and Professor Eric Yu and this was really where I was introduced to the idea of emails being a source of data. I credit these two learning experiences to be the inspiration behind my Ethical AI Workshop project.
My project looks at a framework which uses email data to create process models, searches for areas in the pipeline where private information can be leaked and then suggests ‘privacy guards’ to protect this information.
Declarative Process Mining
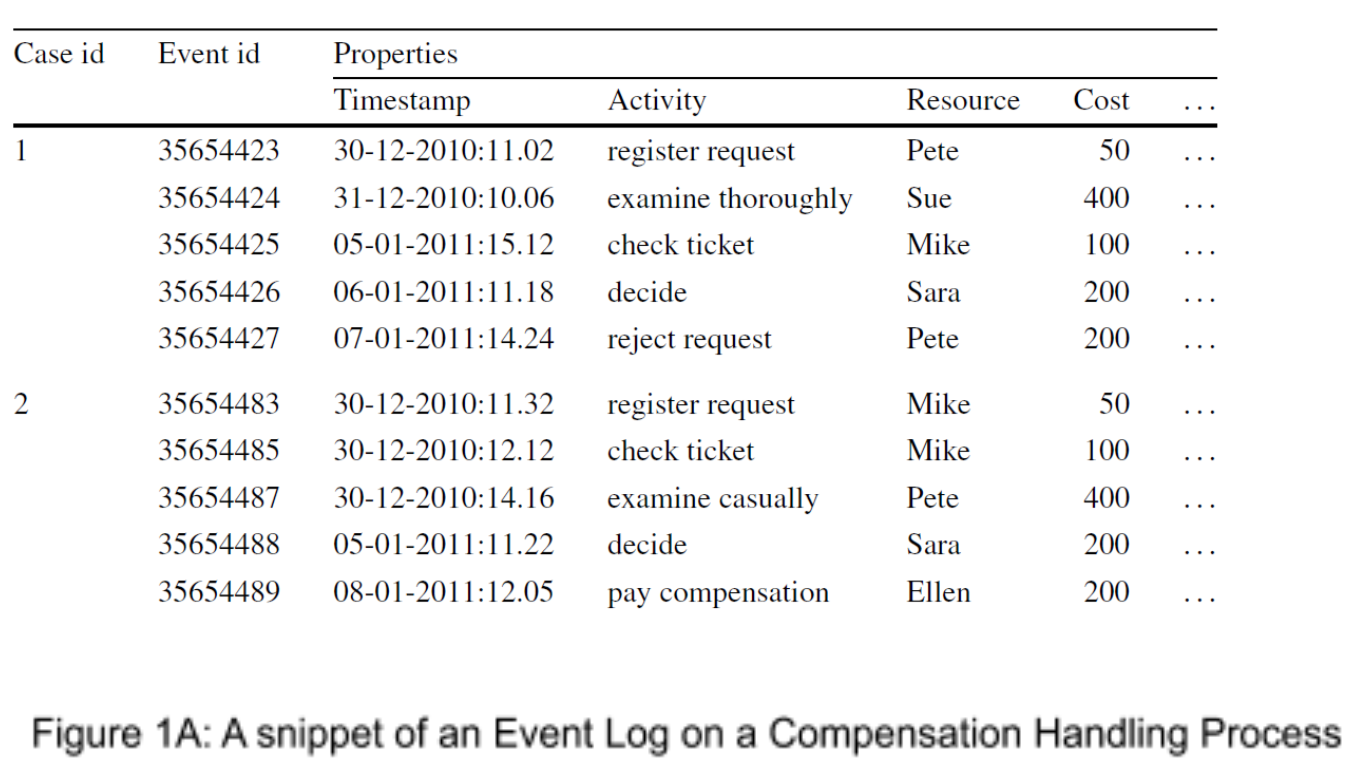
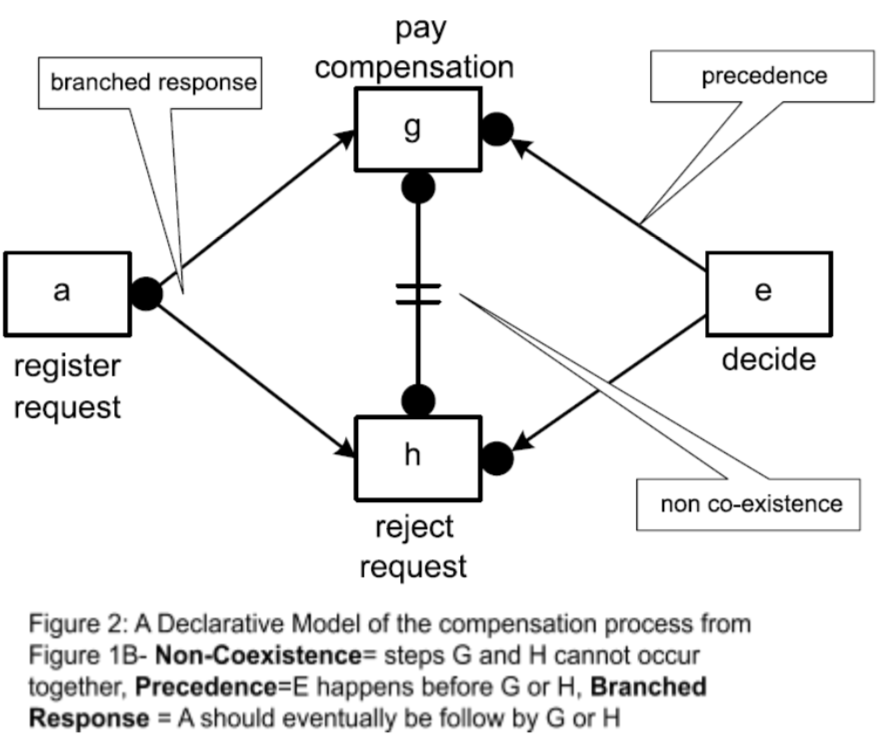
Some procedures within organizations cannot be fully captured by a singular set of rules; they are too flexible in nature. Think of a group report for example: there are meetings at the beginning of a report to assign parts, there are multiple meetings for status updates, sometimes roles get switched around, sometimes a person ends up working on multiple sections, etc. There are many “in the moment” changes that can happen in collaborative tasks. For these mildly unstructured processes, there exists a special branch of Process Mining called Declarative Process Mining. Declarative Process Mining focuses on finding the constraints in a process; finding certain rules in a given process that cannot be broken[1][7]. The DECLARE language is often used in modelling declarative process models (see figure 2) and an example of a few constraints that can exist are shown in figure 3 below[1].

Emails and Privacy Laws
In Canada we have the Personal Information Protection and Electronic Documents Act (PIPEDA) which protects consumers from the collection and use of data in an unethical way[6]. Although privacy laws are meant to protect the interests of consumers and organizations, they can serve as a double edged sword as they can also block the availability of certain types of data, like emails, for analysis. The collection and analysis of email data is a major obstacle as information privacy laws under PIPEDA prevent employers from accessing employee emails without a reasonable cause[6] and the definition of reasonable cause can vary from person to person. In order to overcome this, we are suggesting a method of email mining which preserves the personal information of individuals while extracting the necessary information needed to perform process mining.
So why is the focus on emails specifically? Emails overload is a real problem in many organizations[2]. Emails can serve as a rich source of information to many organizational processes and procedures that may not be well documented and are learned with experience[2]. Office workers are involved in many projects where multiple back and forth communication occurs between people of differing roles and hierarchies. A person who is new to a certain role will learn over time how to manage certain projects but the loss of productive time can build up especially if multiple new people are hired over multiple departments. Email mining can help with documenting the knowledge one gains through experience by having past emails on past projects run through an email mining pipeline to return the steps that are generally taken in the project and the point at which they are taken. The MailofMine Approach

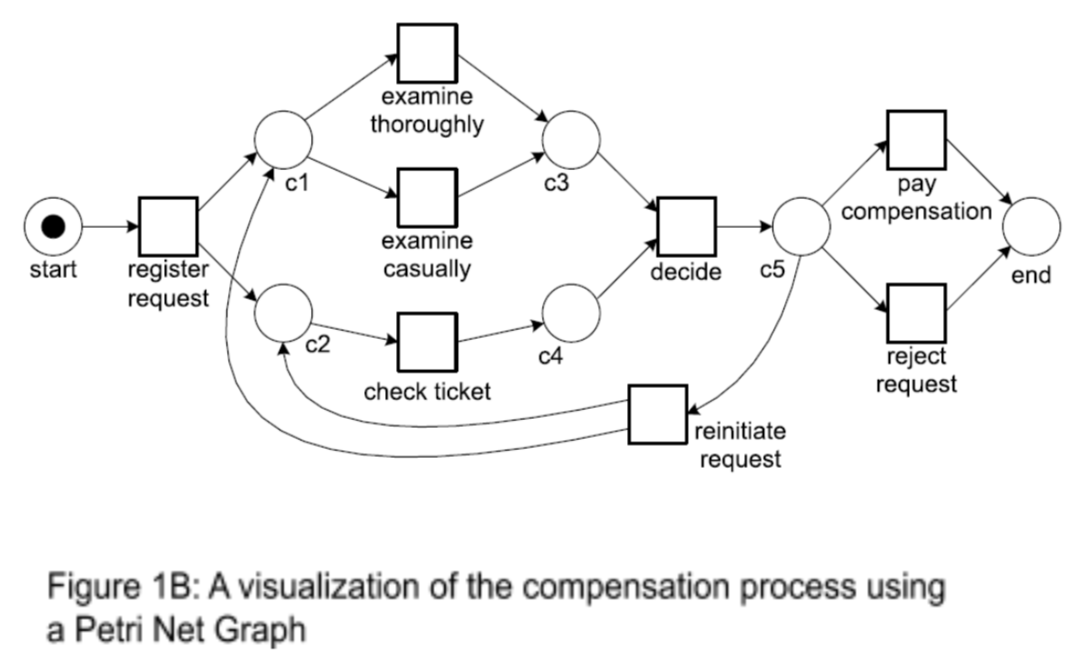
Since communication of collaborations generally happens through email and a lot of back and forths happen in email exchanges, the documented procedures will be very flexible in nature. This extraction of information from emails to form a process model is exactly what researchers Di Ciccio and Mecella modelled in their paper “Mining Artful Processes from Knowledge Workers’ Emails ”.
Their process for doing this is as follows (refer to Figure 4)[1]:
- They took an archived set of emails from a European research Project collaboration, cleaned them of all signatures and cited text from other emails (forwarded/replies) and stored them inside a database.
- Then using a set of user provided vocabulary (provided by a domain expert) and the information retrieval module, the emails that contained specific task related phrases where selected and the others were discarded.
- The selected emails were also ordered according to their timestamps and voila, a sequence of activities performed to complete a task was found.
- In order to undergo process mining and retrieve a process model, the ordered emails must be transformed into an event log. Which is what happened when the emails went through the tracer module. Each task phrase was represented by a single letter to create the ‘process alphabet’ and each letter was placed in order according to the timestamp of the email in which the corresponding phrase appeared in.
- This created the event log which went through the Miner module. In the miner module run a special declarative process mining algorithm called Minerful++ which searches for the constraints in the process.
For example, If a task like ‘submit draft’ never appears before ‘create draft’, then that is a constraint which Minerful++ will discover and represent in the final declarative process model.
Using NLP and Machine Learning in Emails
Natural Language Processing (NLP) is a branch of Machine Learning that takes human readable text and converts it into a digestible form for computers to process (using methods like term frequency-inverse document frequency(tf-idf), word2vec, bag of words, etc). NLP is presently used, in many forms, for email analysis like spam filtering and predictive text [4]. For spam filtering, text classification and Machine Learning Algorithms like Naive Bayes are common techniques. The emails that are flagged by the filter don’t make it to the user’s inbox. Information Extraction which identifies textual pieces of information using parts of speech tagging and chunking (forming noun/verb phrases) is another common application of NLP [4]. These applications can be further extended to preserve the identities and personal information of the employees involved when email mining is performed. The current pipeline does not take into consideration the extraction of private or confidential information when the email bodies are prepared for analysis by the information retrieval module; the emails stored in the database, under the current framework, can be a privacy concern as potential bad actors can hack into the database and uncover sensitive information.
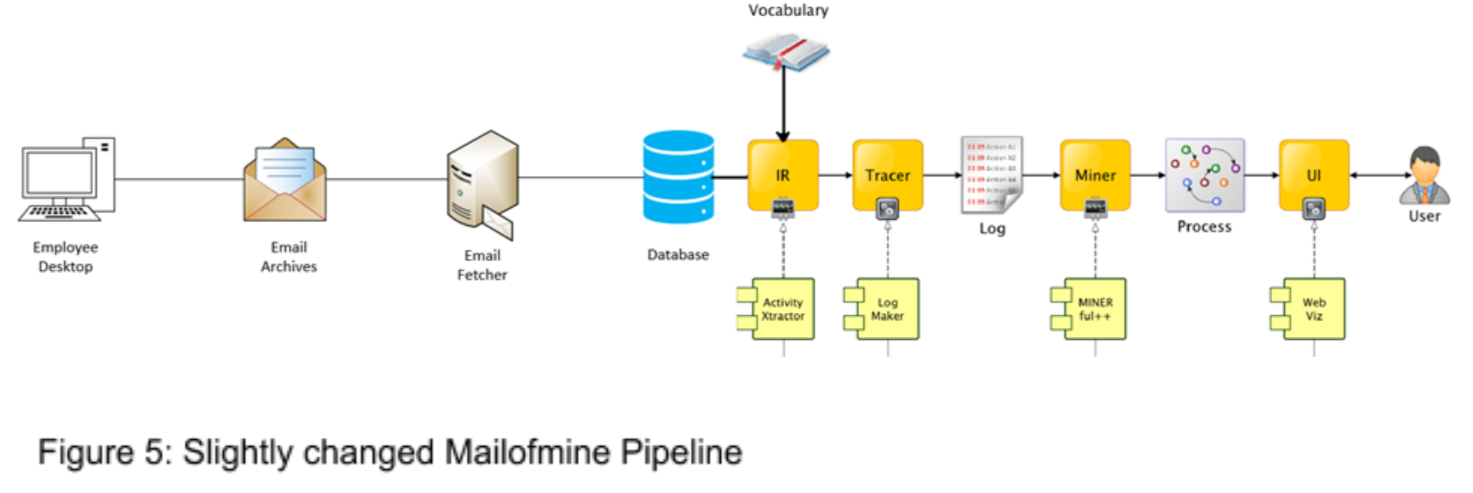
For this reason, we build on DiCiccio and Mecella’s model and suggest applying privacy guards to one of two possible places, each depending on an organization’s intended use of the results of email mining (figure 5).
- Before the emails are archived
- As the emails are fetched from the email client
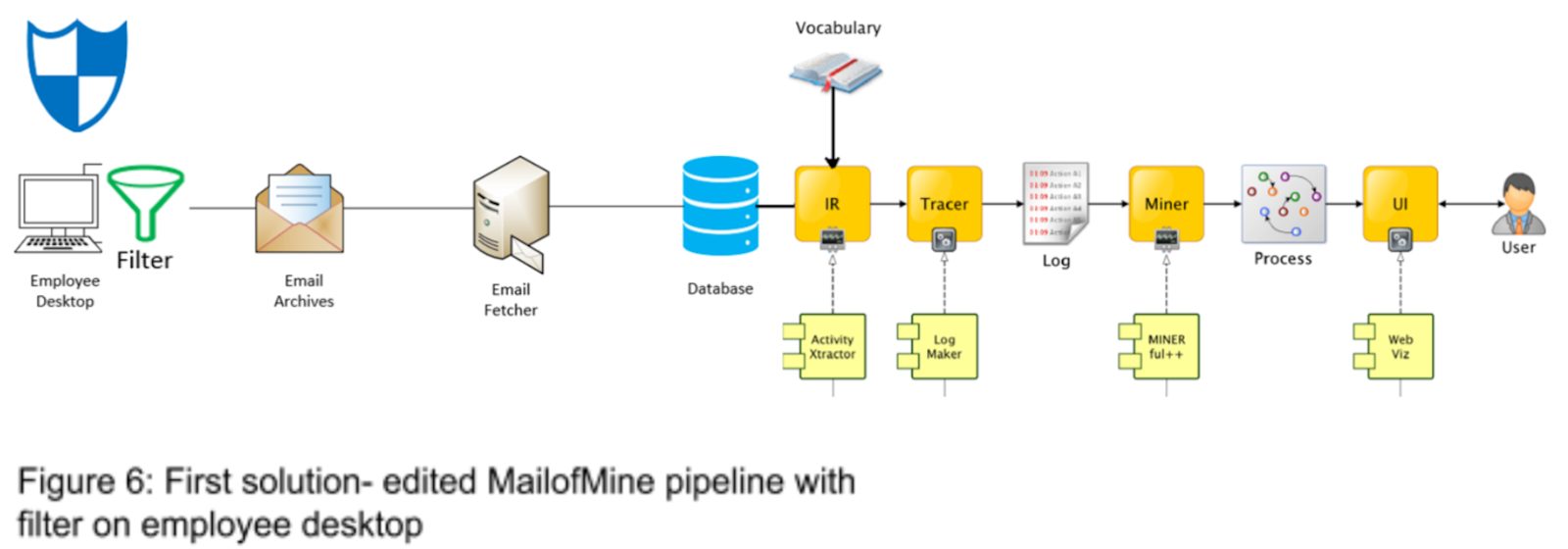
The first suggested solution is to only archive those emails which contain specific words or phrases through the use of a filter on an employee’s email client. The emails would be scanned for user provided words/phrases such as the name of a project or task and would only be archived if certain words are matched (see Figure 6). We can think of this method as a kind of reversed spam filter where keywords are detected before the email leaves the email client and a copy of that email is filed away for analysis. This can be a viable option for organizations who are actively trying to increase worker productivity; the next time a team is working on a similar project, the archived emails (only containing work related information) can be fed into the email mining pipeline and a rough plan or workflow can be suggested to them.
Another solution that can be implemented is to only fetch those emails that contain the user provided collaborative expressions and only store those specific emails in the database (see Figure 7). Other personal or product specific emails will not be matched and therefore people don’t have to worry about bad actors finding out personal information or trade secrets. This can be an option for organizations who want to utilise the knowledge gained by the experience of past employees; once an employee leaves the organization, their emails are mined for project related insights.
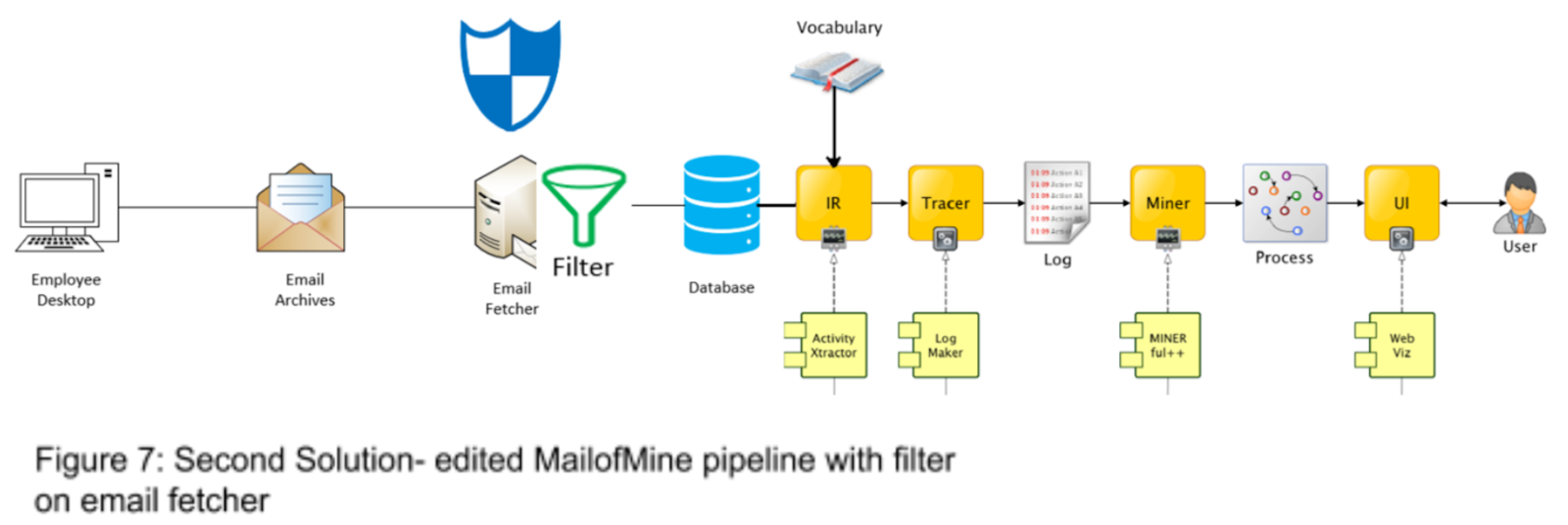
In both cases, the only emails stored in the database are those that are related to collaboration events and the rest of the process would continue as normal.
Future work and Conclusion
Given that this was my first time learning about Process Mining and Machine Learning methods, I did not manage to implement or test the functionality of these privacy guards by the time the EI4AI workshop came around. Future work would be to build on this project and implement these guards on the email pipeline to see how well they actually protect the private data and whether this type of rigorous selection in the beginning stages of the pipeline affects the quality of the information available for process mining. Another potential direction this project can take is to eventually move away from the use provided vocabulary altogether by utilizing text summarization algorithms to create structured project related email subject lines which can make the email mining process faster. No matter what the solution, human oversight is critical for this process to remain secure. I will continue to feed my curiosity of Process Mining by taking the official course offered at iSchool, which is also taught by Professor Senderovich. I would look forward to building on this work during the course, if possible.
This blogpost was a summary of my summer project and I hope it showcases how Process Mining Applications like the MailofMine Approach can help organizations with inefficiency problems like email overload. Apart from the technical details of the project, it should also be noted that the development of innovative laws and methodologies that permit the ethical use of private information are necessary for the improvement of organizational productivity and the quality of life for its employees.
References
Images from figures 3,4,5,6 are taken from the Di Ciccio and Mecella paper, figures 4-6 are edited
Images from Figures 1 and 2 are taken from the Process Mining textbook
[1] C. Di Ciccio and M. Mecella, “Mining Artful Processes from Knowledge Workers’ Emails,” in IEEE Internet Computing, vol. 17, no. 5, pp. 10-20, Sept.-Oct. 2013, doi: 10.1109/MIC.2013.60.
[2] Dabbish, Laura & Kraut, Robert & Fussell, Susan & Kiesler, Sara. (2005). Understanding email use: Predicting action on a message. 691-700. 10.1145/1054972.1055068.
[3] Dumas,M., La Rosa, M., Mendling, J., Reijers, H.A. (2017). Introduction to Business Process Management In Fundamentals of Business Process Management (pp. 1-12). Berlin, Germany: Springer.
[4] Khurana, Diksha & Koli, Aditya & Khatter, Kiran & Singh, Sukhdev. (2017). Natural Language Processing: State of The Art, Current Trends and Challenges.
[5] Lampert, A., Dale, R., & Paris, C. (2009). Segmenting Email Message Text into Zones. EMNLP.
[6] Rice, D.M., Bogdanov, E. (2018). Privacy in Doubt: An Empirical Investigation of Canadians’ Knowledge of Corporate Data Collection and Usage Practices
[7] van der Aalst, W.M.P. (2011). Process Modeling and Analysis In Process Mining: Discovery, conformance and enhancement of business process (pp.29-57). Berlin, Germany: Springer.
